
Adiscon’s open source log analysis frontend LogAnalyzer has grown with some exciting new features. Most importantly, report generation speed has been much increased. This was made possible via tighter integration of the report logic with the actual log source (database or file). As a result, all reports are generated in considerably less time and require far fewer system resources to complete. Along the same lines, Adiscon LogAnalyzer now offers suggestions for indexing database sources. If it finds room for improvement, new indexes are automatically suggested. This results in overall improved speed throughout the application.
Also, finally a long-due user interface improvement has been made: to access the reporting feature, users needed to access the admin panel. This was kind of well-hidden and cumbersome. In 3.3.0, reports are directly available from Adiscon LogAnalyzer’s main panel. With this change, some users may even discover the reporting feature for the first time. The screenshot below gives you a sneak preview of the new interface.
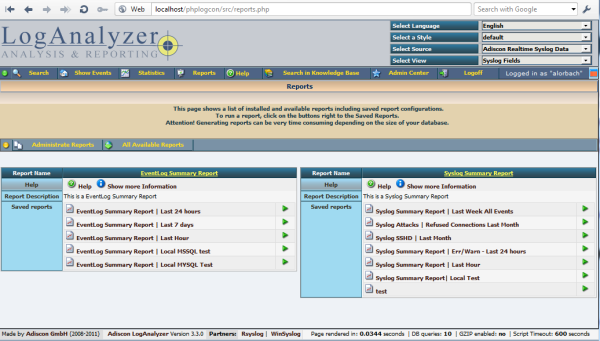
Best of all, the new version has brought some under-the-hood improvements that we will utilize in the future to generate some really exciting new reports. Stay tuned, there is much more to come…
And finally let me say that work with the LogAnalyzer team to improve integration into rsyslog and the Adiscon’s Windows logging components. We are trying very hard to provide an easy to use, integrated solution.