Liblognorm is already one of the fastest log normalization tools available – if not the fastest. But, believe it or not, it will get even faster soon!
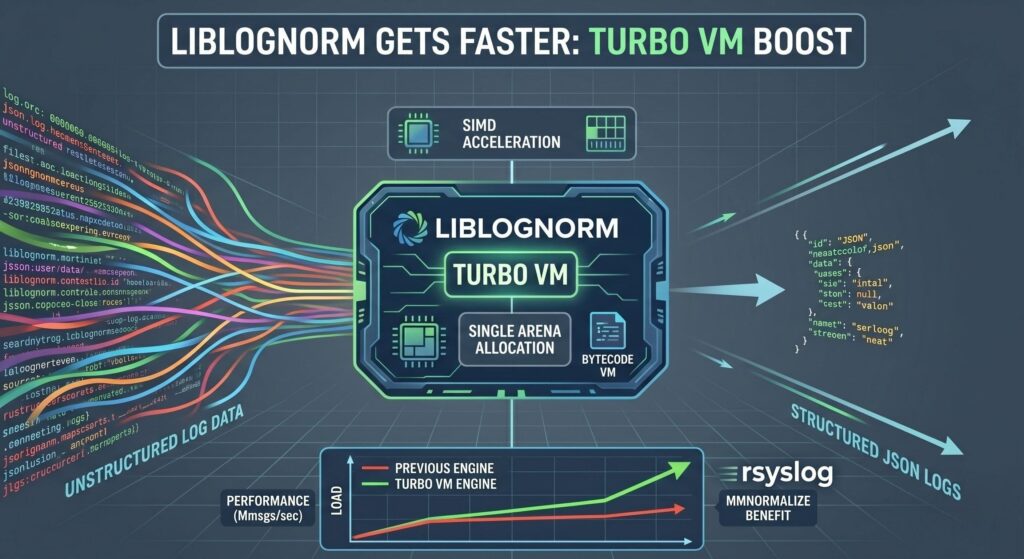
We received a great Pull Request from Jérémie Jourdin, a key person behind aDvens. It introduces the so-called “Turbo VM”, a new optional bytecode execution engine for liblognorm that compiles rulebases at load time and executes them in a fast linear VM. On supported platforms, it uses SIMD-accelerated parsing primitives, and it also replaces many small allocations with a single arena per message.
Continue reading “Liblognorm will get even faster – and so will rsyslog!”