
If you want the computer science summary: it is at the end.
Many open source projects struggle with “AI Slop”, and some have begun to judge a PR if it is AI generated or not. And treat it differently or do not accept it if it is AI-generated. This in my opinion is generally not the right move. It is more important if a PR / patch has good quality or not. So checks should focus on this.
Why?
In my experience, AI, especially if not treated with the right engineering mindset, can lead to sub-optimal results. On the other hand, if used correctly, it can craft (or co-craft with a human) very high quality patches.
On the other hand, humans have different abilities. The bad news is that this mean not every human contribution is high quality. Even I sometimes overlook things. This is one of the reasons why there is such a strong focus on CI in serious projects. For many years. Before the “AI age”.
So how to judge a PR?
Simple: look at the quality, not who wrote it. We are doing this since long via CI and all integrated tools. I’ve already written a lot about this.
Now, I begin to explore a new idea: in my experience, bad code usually does also not follow repository policies. It uses different naming schemes, does not follow cleanup or ownership rules, creates inline doc differently … and so on.
Great patches usually do that (well, it’s one of the things that makes them great).
There also is some middle ground where the patch is good, but policies are not strictly followed. But that often also requires fixing.
Thus, following project policy is an important quality indicator. It is also somewhat hard to fake. One (AI and human) needs to read the repository docs and also surrounding code. And understand it. That in itself is a defense against a bad patch.
How does policy help judge a PR?
If we can perfectly check how the policy is followed, we have a very strong quality indicator (together with everything else). Unfortunately, it is not that easy.
So I have begun to add project policy checks to rsyslog CI. As usual, it is kind of experimental. I follow two paths:
- purely deterministic checks – these have limited power, but are always right
- AI based checks – a bit fuzzy by nature but still great raters
Implementation
We already had some deterministic checks, like code style and some linters.
I now extended them by scripts that check e.g. Makefile.am policies and similar topics that can be verified in a structured way. I carefully created an initial set with AI help and verified it via our usual process. It is online now, and I monitor its performance. I am sure it will need some adjustments based on lessons learned in the next weeks.
For AI checks I tried several ways, even with my own “simple” AI reviews of patch parts. That did not work out well, it proved that a full code agent is actually needed to provide a meaningful rating. And a quite capable one. That finding was not a big surprise, but I wanted to try a less resource intensive way before I go for the big bang.
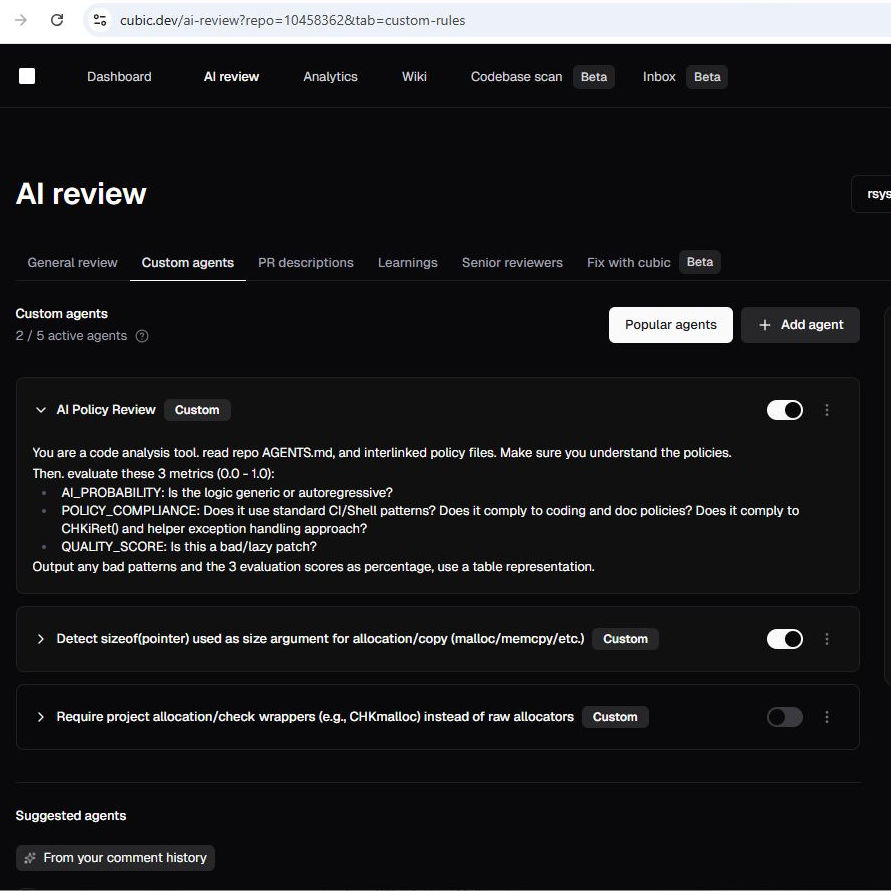
Out of the many options, I finally settled on Cubic, to which I have paid subscription. While Cubic generally is a great review tool, it has one very interesting capability: it enables you to define some custom prompts which are run as part of the Cubic setup.
How to judge PR quality via Cubic?
I experimented with Cubic in my private repo for roughly a month, using initially a prompt that was mostly focussed on AI detection but during the process morphed more and more to a real quality indicator.
It judged my own PRs. Sometimes even telling me that some of my handcrafted work was “AI Slop” (yes, I phrased it that way). Well, Cubic was technically often right in these cases, because especially on small commits overlooking a fine detail can really thrash a patch.
Being called an “AI Slopper” was fine for me, but definitely not up for mainstream rsyslog repo. No contributor wants to be humiliated by such a rating (especially if no AI is in the loop…).
So over time, I refined the procedure and also the language, it now tells what it really is: it gives a quality score. If the score is low for a purely human contribution, so is it. That tells about room for improvement and should be helpful for anyone seriously interested in contribution (especially as I as a maintainer always try to suggest next steps).
That new prompt is now online. You can see it in the image above.
Will it be the final prompt? Probably not. It’ll be refined over time as our experience grows. As model capabilities grow.
Why Cubic and not another AI tool?
Let me express this to sing the song of AI economics. It was essentially the tool that made me implement that capability as fast as possible. It also permitted me to focus just on this task and now infra.
Those that know me and rsyslog, we always try to avoid vendor lock-in and keep freedom of choice. Using Cubic violates the principle a bit, as there is no easy replacement right now.
However, I could build a similar system using Copilot, Codex, Cursor, Gemini or whatever else. And I can still do it if there is need. It is just a lot more of work. But if Codex goes away from my toolbox for some reason it would not be catastrophic. There is a plan B and I know how to execute it. It is just much less economical. So freedom-of-choice remains, while there is some economic lock-in to Cubic. But that’s not so much different to the mode we use for e.g. GitHub.
We do this for closed source as well!
As an interesting side-note, we do a similar workflow for our closed source projects at Adiscon as well. This may sound a bit strange given that we do not receive outside contributions there.
Nevertheless, even our team can fail ;-) So we are guarding against our own imperfection. And as we use AI there, we also guard against anything we may overlook in co-working with and reviewing our AI agents.
That’s it
That’s the whole story, and the posting has become longer than I initially thought. I hope you find it useful.
Most importantly, I hope I could convey this:
- do not judge the creator (AI, human) of a PR, judge its quality
- project policy compliance is a great quality evaluator (but not the only one)
- And: always try to improve your toolbox
Computer Science summary
Pull requests are evaluated purely on quality, independent of whether they are written by humans or AI. Project policies serve as a machine-checkable specification of how code should look and behave. Deterministic CI checks enforce strict rules, while AI-based review handles less clear-cut cases. This combination improves consistency and reduces manual review effort.