
Liblognorm is already one of the fastest log normalization tools available – if not the fastest. But, believe it or not, it will get even faster soon!
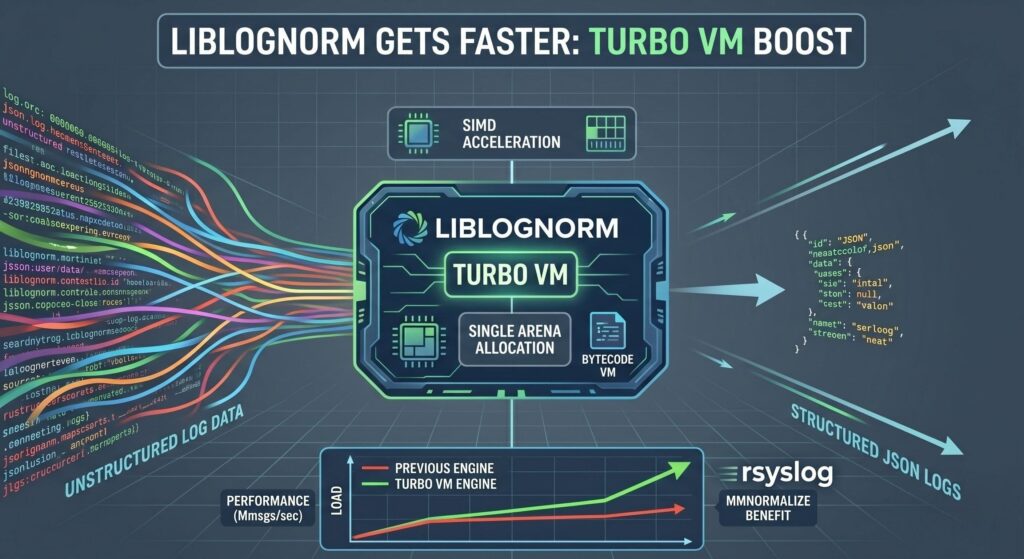
We received a great Pull Request from Jérémie Jourdin, a key person behind aDvens. It introduces the so-called “Turbo VM”, a new optional bytecode execution engine for liblognorm that compiles rulebases at load time and executes them in a fast linear VM. On supported platforms, it uses SIMD-accelerated parsing primitives, and it also replaces many small allocations with a single arena per message.
TurboVM was written by aDvens from scratch directly for liblognorm. It is not an existing aDvens component and not an external library. The result is a substantial architectural step forward, while staying fully optional and preserving compatibility with the existing engine.
How is it possible to make liblognorm even faster?
Liblognorm is fast because of its algorithm which works in constant time – O(1) – in most practical deployments. So how can it become even faster?
The reason is simple, and sometimes tends to be overlooked in theoretical reasoning. If the time is constant, that does not mean the time is “quick”. Liblognorm already used pretty optimized patterns inside the code. But we walked the tree and manipulated JSON as we processed the data. Even in the original lognorm paper that liblognorm implements, there was a hint at this “improve the performance of those third-party components. We have actually done this by developing libfastjson based on json-c. Also, replacing the system
default memory allocator by jemalloc usually results in increased performance.” (p. 65).
The Pull Request in essence addresses this fact. And as such, it removes the probably most important bottleneck. Consequently, the actual execution time for lognorm processing shrinks even further.
This is probably the most important contribution we have received since liblognorm was designed and implemented.
Not a one-shot PR
It is also worth noting that this is not a singular event. Jérémie and his team at aDvens are regular and consistent rsyslog contributors. We already received numerous great pull requests from them in the past couple of years.
So it comes at no surprise that there is also a matching PR open against rsyslog, which also enables these liblognorm enhancements for mmnormalize, rsyslog’s normalization component.
Even better, more work is promised to come.
There is also much more to tell about rsyslog and aDvens – but that is a story for another day.
Un grand merci a Jérémie et a toute son equipe chez aDvens pour cette excellente PR, ainsi que pour une collaboration de grande qualite depuis de nombreuses annees.
Please also see Jérémie’s post at the aDvens site for even more insight about this work. It also shows a great benchmark.