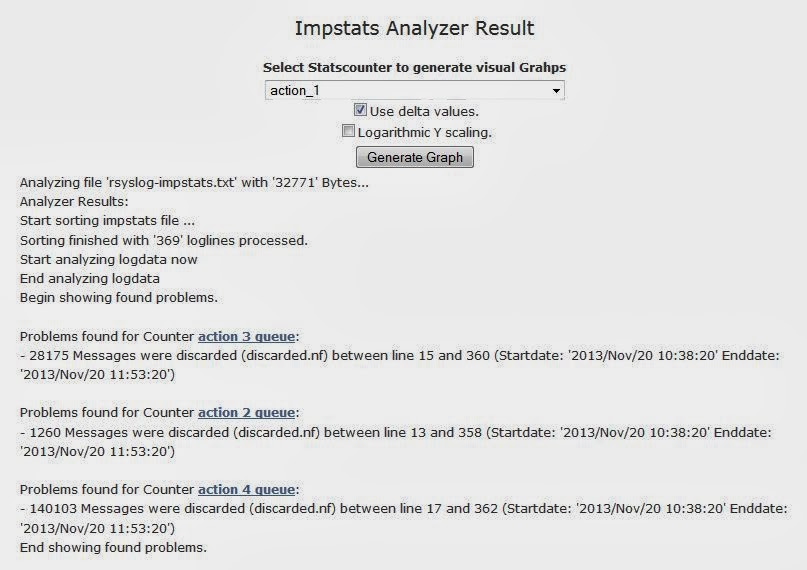
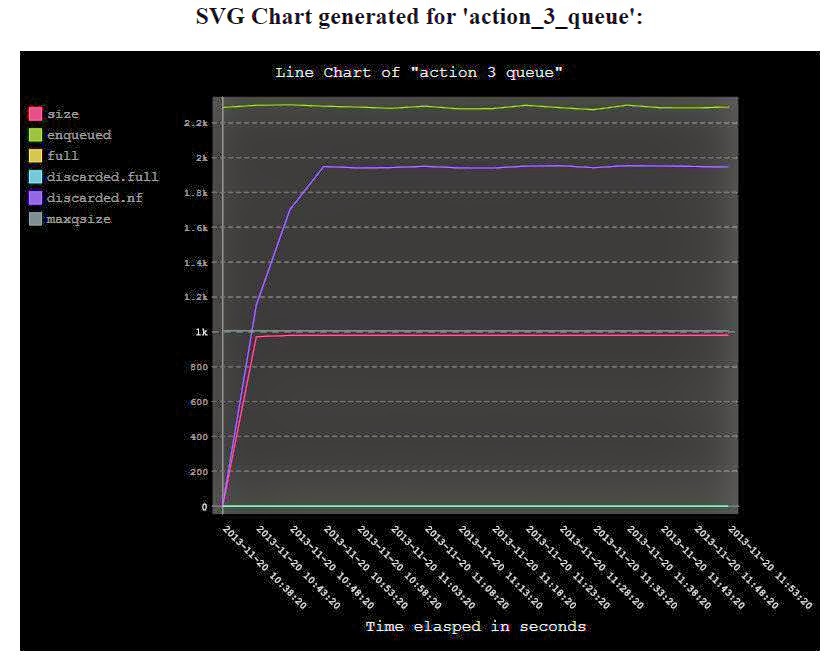
Rsyslog is an enterprise-class project. Among others, this means we need to provide different versions for quite a while (enterprises don’t like to update every 6 month, and don’t do so for good reasons).
As such, we support multiple major versions. As of this writing, the versions used in practice are v5, v7 and v8 upcoming shortly. There are also v0,…,v4 versions out there, and what I write applys to them equally. If there is development going on for a version, there is a vX-devel branch. This is for those that want the new features, obviously at the expense of some enhanced chance for instability. And then there is vX-stable, which is the stable branch. Once something is named vX-stable, it NEVER receives new features, just bug fixes. There is one exception from the naming rules: the most current development version is held inside the git master branch — because that’s where people expect it. So, currently, there is no v8-devel branch, but it’s named “master” instead.
Maintaining multipl versions sounds scaring and cumbersome. Indeed, this fear came up when talking about maintaining multiple doc versions inside the rsyslog-doc project. Thanks to git, this is not the case. It’s actually dumb easy to do, once you get a little used to the workflow.
The key thing is to make changes in the oldest branch where they belong (with “oldest” being the one that the project really want’s to support). So if there is a bug that’s present in v7-stable, v7-devel and master, do NOT fix it in master. Checkout v7-stable and fix it there. The same applies to doc updates. Once you have fixed it, all you need to do is to merge the changes up. Especially for smaller changes, git does most of the hard plumbing. Occasionally, there may be some merge conflicts, but these can usually quickly solved. There are some rare exceptions, usually as the result of big refactoring. For doc, merge conflicts are always almot trivial to solve (at least have been in the past). It’s advisabile to merge up early. The longer you wait, the more work you need to do if a merge conflict occurs (because you probably don’t remember well enough what you did). The backdraw of that is that the git history becomes a little cluttered with merge entries, but that’s how it is (nothing in life is free ;)).
So in the workflow is as follows (I use the v7-stable as the “oldest” version in this workflow sample; that’s also the typical case):
- git checkout v7-stable
- update whatever you need to update
- git commit
- git checkout v7-devel
- git pull . v7-stable
- git checkout master
- git pull . v7-devel
- DONE
In esscence, you make the change once and take 30 seconds to merge it up. Merge conflicts happen seldom and are quite unlikely for doc changes. Those that happen are usually just additions to related areas, and so it takes another 30 seconds to fix them. All in all very painless.
If you check the git logs, you’ll often find occurences of the workflow above (just look for the merges, they really stand out).
Now there remains the question of multiple versions, not branches. For example, we have v7.4.0, 7.4.1, 7.4.2,… How do we handle updates to them. Well, easy: first of all when 7.4.x is out, 7.4.(x-1) is NEVER again change (why should it, that’s for the next version). So we actually do NOT do any updates to already released versions (again, think about the resulting mess). So it just boils down to being able to fetch the exact same version later. And this is extremely easy with git: just use a tag, that’s what this is meant for.
So whenever I do a release, the last thing I do after it is build and being announced is do a “git tag “, e.g. “git tag v7.4.7”. That way, I can later do “git checkout v7.4.7” and have exactly the version I look for. Note, though, that you need to do “git push –tags” in order to push the tags to your published repository.
Conclusion: using git branches and release tags makes it extremely easy to maintain a multitude of version. Without git, this would be an almost undoable task (we had a really hard time in those CVS days…).