
The past day’s rsyslog work log:
2008-01-11
– undid part of yesterdays stage work – q worker 0 does not have management
chores, will use another solution (not needed yet)
– begun to permit queue to terminate without being drained
– fixed a starvation condition in queueWorker (pthread_yield() was needed)
could not be seen with any previously released code, came up during
new development
– added $MainMsgQueueImmediateShutdown config directive
– some name cleanup
– added non-circular file stream mode
– added some debug instrumentation to obj_t type, so that invalidly passed
objects can be detected (else we use the jump table and do not know why
everything messes up)
– file stream objects are now persistent on immediate queue shutdown (queue itself
is not yet fully persisted)
– support for object property bags added
– queue can now persist disk queue information on immediate shutdown
– added function to de-serialize a property bag (untested as other code is yet
missing)
– support for de-serializing strm objects added
– partial ability to read a disk queue back in (not completed, but would like
to save source for the weekend)
2008-01-13
– support for reading back persisted queue information completed
– added $MainMsgQueuePersistUpdateCount config file directive
– renamed $MainMsgQueuePersistUpdateCount config file directive to
$MainMsgQueueCheckpointInterval
– changed queue shutdown procedure a bit – stage work for queue shutdown
timeout setting
rsyslog work log update
rsyslog work log for Jan, 9th and 10th (sorry, forgot to post yesterday):
2008-01-09
– implemented new GetSize() handler for config files
– implemented $MainMsgQueueMaxFileSize configuration directive
– implemented queue object method to set the file name prefix
– implemented $MainMsgQueueFilePrefix configuration directive
– created a generic stream class (for file access)
– changed queue class to use stream class
– some cleanup on object model
2008-01-10
– changed queue file name generation (to be more generic)
– made queue file names better readable
– added buffered output to stream class
– data record support added to stream output writer
– added write functions for several types to stream class
– changed objSerialize methods to work directly on the stream class
– prepared for 3.10.1 release
– changed some config parameters and some cleanup
– released 3.10.1
– fixed a bug that caused a segfault on startup when no $WorkDir directive
was specified in rsyslog.conf
– fixed a bug that caused a segfault on queues with types other than “disk”
– removed the no longer needed thread TermSyncTool
– re-released 3.10.1
– implemented strm object serializer (untested as the code required for test
is not yet present – hen/egg problem…)
– some cleanup
– implemented management function for worker thread 0 in order to change
queue workers dynamically — stage work
STS-122 Launch in early February?
 As it looks, Atlantis will launch no earlier than February, 2nd on its STS-122 mission to the international space station. Some new problems have popped up and also been fixed since my last blog post. Unfortunately, I am currently quite busy with some of my projects and so I could not follow as closely as I usually did. However, I checked the status today and all in all it seems to look quite OK.
As it looks, Atlantis will launch no earlier than February, 2nd on its STS-122 mission to the international space station. Some new problems have popped up and also been fixed since my last blog post. Unfortunately, I am currently quite busy with some of my projects and so I could not follow as closely as I usually did. However, I checked the status today and all in all it seems to look quite OK.
Tomorrow is another NASA PRCB meeting (they are each week on Thursdays). I expect that we will see an official status update on potential launch dates. In the mean time, tests on the external feedthrough connector removed from Atlantis’ external tank are being conducted. This is not yet completed and it will be interesting to see the test results.
At the launch pad, the cables have been soldered to the connector, giving them a solid connection. This very same fix was applied to Atlas rockets with similar issues some years ago.
In short, there actually is currently not much to report. The wizards at NASA are working very hard to find the actual root cause and a good fix for the ECO sensor issue. There is not much definite know today because it all depends on the outcome of testing and analysis. So lets stay tuned for what’s going on…
Vodafone Customer Service Misery…
I wanted to share my experience with Vodafone Germany’s customer service. And, yes, I have to admit I am a bit upset…
The story begun just after Christmas, roughly two weeks ago. I ordered a phone online and the shop said it would take around two business days. With the holiday period, I wasn’t much surprised that nothing happened in 2007, but I had expected a delivery early this year. Well… it took some time, but last Friday a delivery man showed up in the office, of course when I was away. But he couldn’t leave the phone for me, because he was required to collect money for it (that’s fine), but could not find out how much (that sounds a bit silly, doesn’t it?). He promised to find out and come back either the same day or this Monday.
Well, of course nobody showed up. Being patient as I am ;), I waited until today before I even wanted to have a casual look what’s going on. The confirmation mail I received after my order contained a web link that should provide status information. Nice. Not so nice is that all I could get out of that page was the fact that the application developer had obviously forgotten to handle some Java exceptions (“javax.servlet.ServletException: Error while looking for EJB” – not exactly what I was looking for…).
OK, software can be buggy, so not a big deal. I called their hotline. Well, I tried to. First thing was that there was no phone number listed at all. Bad. So I resorted to the general Vodafone hotline. The expected happend: I ended up in he wait queue and was served that nice music. But, after roughly three minutes, the unexpected happend: “all of our Agents are still busy, please call us again later” the computer voice said – and quickly hung up the phone. Ummm… not nice. So was I supposed to call back again and start at the beginning of the queue? Looks so (oh man, would I like to have the QUEUE_ENQUE_IN_FRONT setting available to me…). I have to admit that at this point in time I was already a bit annoyed.
I called again. The very same happened. Some time later, I called back again… hangup, too. At this point, I sent a quite angry email to their contact address. I have to admit that it was brief and somewhat impolite and I expressed my expectation that the mail would most probably go to /dev/null immediately. Guess what? I got an auto-responder reply. Of course, a human reply is yet to be seen…
I tried to call the hotline again from time to time, but always I received a hangup after an apparent three-minute timeout (their system seems to be even more impatient than me). So it is obviously impossible to contact Vodafone customer service at all.
Maybe that should staff up their call center – or look for a phone provider who is capable to handle a larger caller queue…
rsyslog work log for 2008-01-08
Yesterday’s rsyslog work log:
2008-01-08
– fixed doc bug — thanks to varmojfekoj for pointing it out
– fixed some memory leaks in new code — thanks to varmojfekoj for the patch
– implemented queue disk reader to switch to multiple files
– first implementation of “disk” queue mode finished. It still needs some
work and the deserializer needs also to be expanded, but the queue at
least performs well now.
– fixed a race condition that could occur when input modules were terminated
– added –enable-mudflap ./configure option
– completed deserialization support in msg object (but not deserializer itself)
– completed object deserializer
work log for 2008-01-07
rsyslog work log. I am currently totally focused on the queue (and thus not very responsive on mail and otherwise):
2008-01-07
– released 3.10.0
– performance-tuned stringbuf class
– implemented disk queue as far as I could without an object de-serializer
– implemented buffered read calls for the queue file
– implemented class type registry
– MsgSetProperty() implemented
– defined a property class
– implemented deserializer (needs some more work)
rsyslog work log for 2008-01-06
Here is the rsyslog work log for yesterday:
2008-01-06
– fixed a bug with integer conversion in srUtils.c
– changed some lib functions to work on long instead of int
to care for 64 bit platforms (just to be on the save side)
– worked a bit on object serialization
– cleaned up msg structure (interestingly, there were for example
two fields with identical meaning and iSyslogVersion was never
used ;))
– completed serializer for msg (but needs review)
– did a little bit performance cleanup
– worked on object header (now also contains the size)
rsyslog threading
If you followed my work logs or CVS updates, you’ve probably seen that I have worked quite a bit on rsyslog‘s threading. So I thought I share a view “design documents” that cover up the big picture.
Michael Biebel asked me for a few graphical representations of how the modules interact and what the message flow is. I am not a real good computer graphics guy, and an old-fashioned one. So I thought before I let you wait any longer, I share some of my hand sketches. They are not fancy, probably hard to read – but maybe still helpful. Find them below. A klick bring up the hires version, which is a bit less hard to read ;)
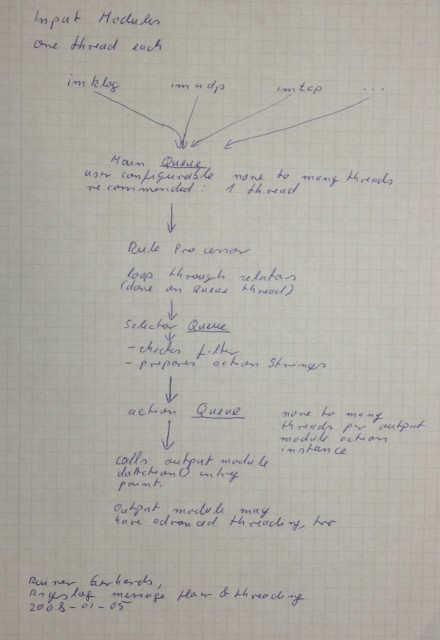
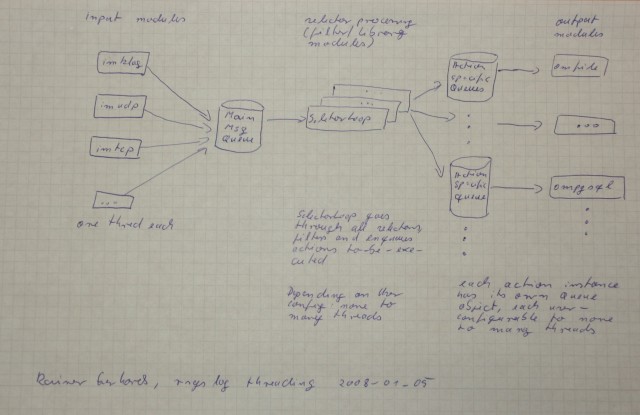
I’ll try to add better graphics and descriptions as soon as I find some time. But I have to admit that I currently have so many things on my mind that I’d like to code first. So it may take a short while.
recent rsyslog work
Here is the rsyslog work log for the past days:
2008-01-03
– fixed a few typos noticed by Jonathan Smith – thanks
– moved queue code to its own module (finally)
– restructured queue interface to use rsRetVal and instances, removed
dependency on globals – now more like a real class
– implemented queue type “drivers”
– queue is now a full object and handles threading by itself
– applied Michael Biebl’s patch to clean up the makefiles
– added capability to use a linked list for queuing to the queue class
– added $MainMsgQueueType config parameter
– some cleanup
– added $SpoolDirectory config parameter
– added $MainMsgQueueFilePrefix config parameter
– begun working on disk queueing (not completed, do not use this mode!)
– begun some work on Msg Object serializiation
2008-01-04
– created a kind of general base class
– removed serialization pointer from queue; used new base class instead
– utilized the new auto-destruction capability so that the queue can now
destruct user objects if needed
– changed queue object Construction/Startup interface
2007-08-05
– added capability for concurrent access to the msg class. Can be dynamically
activated. If active, locking is employed.
– added the “direct” queueing mode to queue class (no queing at all)
– added multiple worker thread capability to queue class
– implemented $MainMsgQueueWorkerThreads config directive
– removed some no-longer-needed code (thanks Michael Biebl for the help)
Atlantis to launch on January, 24th?
The NASA space shuttle home page currently states that Atlantis could possibly launch on January, 24th. However, there are serious doubts about that date. From what I have found on the net, early February sounds much more realistic – with a launch on February, 2nd if there will be no further tanking test conducted. The most likely scenario, however, seems to be a launch no early then February, 8th.
Unfortunately, I am currently very busy with one of my projects and thus can not report more in-depth. That will follow hopefully soon. In the mean time, let me quote the NASA shuttle home page:
NASA flight control teams and ground operations teams have been requested to protect for a Jan. 24th launch date for Space Shuttle Atlantis. As work progresses, that date will be modified as required, says John Shannon, deputy manager for the Space Shuttle Program. The schedule depends on test results and modifications to a fuel sensor system connector on the external fuel tank Atlantis will use for launch on its STS-122 mission to the International Space Station. Other launch opportunities could come between Jan. 24th and the first week of February.
The connector suspected of prompting false readings during two previous launch attempts is undergoing intensive testing at NASA’s Marshall Space Flight Center in Huntsville, Ala. Engineers also will test potential modifications to the connector to certify it for flight. Marshall has a test facility that allows the connector to be subjected to the same conditions it saw during the earlier launch attempts.
The modification and testing plans were discussed along with the launch preparation schedule during a meeting of Space Shuttle Program managers Thursday.
Technicians at NASA’s Kennedy Space Center, Fla., will modify a replacement connector for the one that was removed. Metal pins inside the connector will be soldered to the socket, Shannon explained. The new connector is scheduled to be in place by Jan. 10.
“We’re fairly confident that if the problem is where we think it is, that this will solve that,” Shannon said.
Atlantis remains at the launch pad as the agency studies ways to modify the connector. The shuttle will carry the European Space Agency’s Columbus laboratory to the space station during the STS-122 mission.