
Creating a pull request is simple. But creating a really good pull request seems to be a different beast. If you follow some simple rules a great PR is easy to create:
Squash your Pull Requests!
PRs should include one commit per feature or bugfix – but not more. Especially fix-up commits are really bad and we try to automatically reject them.
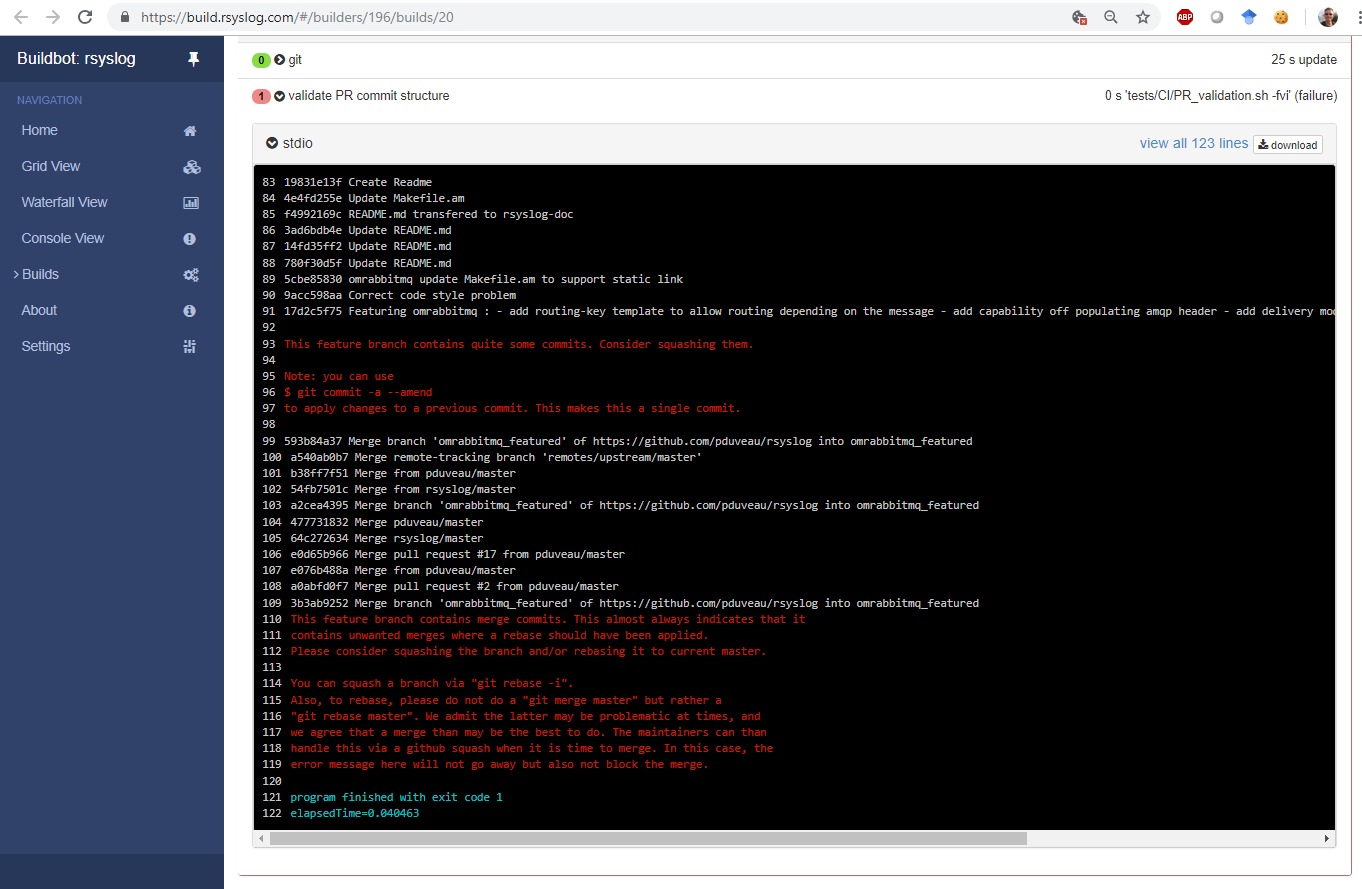
A fix-up commit is one that fixes a previous commit within the same PR.The key point is that it does not correct a current coding bug, but one that would have been introduced in the same PR. The proper thing to do is melt it together with the commit that made the mistaken. It is best to not even create the fix-up commit in the first place. Use “git commit –amend” when applying the fix.
There is a hard technical reason why fix-up commits are bad: git bisect provides an easy way to find regressions. When there are commits that do not build (or where tests fail), git bisect does not work. Continue reading “Squash your Pull Requests!”
Understanding CodeCov Reports
We use the CodeCov Tool inside rsyslog CI processing.Obviously, this can cause CI failures, which then look similar to these:
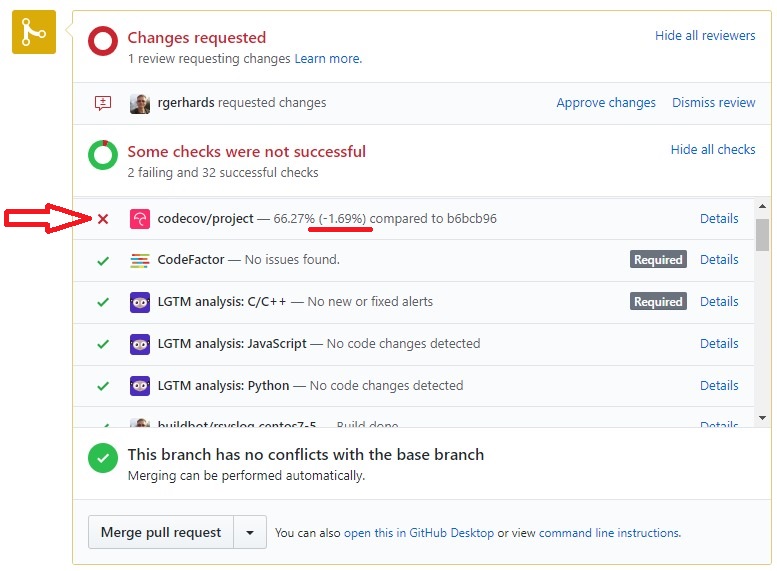
This sometimes triggers questions from contributors on what to do against it. Continue reading “Understanding CodeCov Reports”
Finally … rsyslog Minimum Batch Sizes
Today’s release of rsyslog 8.1901.0 contains a small but important feature: the ability to specify a minimum batch size. It is much-needed for some outputs, with ElasticSearch (and ClickHouse) being prime examples. While I am happy I finally implemented it, I am also a bit ashamed it took me almost three and a half year since Radu Gheorghe proposed that feature in 2015.
Quick reminder on how rsyslog batches work: we receive messages and put them into queues. From these queues, we pull so-called batches (sets of messages) and have them processed by output modules. A batch can contain a given maximum number of messages (by default and depending on case around 1024 or below). If there are that many messages inside the queue, a full batch is extracted and processed. If the queue does not contain that many, whatever it currently has is taken and forms the batch. As such a batch contain as few messages as one. Continue reading “Finally … rsyslog Minimum Batch Sizes”
German-Language Site going online…
I am starting a dedicated site in German language. It is available at www.rainer-gerhards.de. The site will differ considerately from this one here, it won’t just be a translation. It will focus primarily on local things and those that my fellow Germans will probably be more interested in. The focus of this site here will remain as is and will of course be updated.
rsyslog version numbering change
As we know, rsyslog uses a version number scheme of
8.<real-version>.0
where we increment <real-version> every 6 weeks with each release. The 8 and 0 are constant (well, the 0 could change to 1 with a very important patch, but in practice we have only done this once).
While this scheme has worked pretty well since we introduced it, I often see people not understanding that there is really a big difference between 8.24 and e.g. 8.40. Looking at recent trends in software versioning, we see
- single-number versions, e.g. in systemd
This is actually what we use, except that we make it look like and old-style version number by the prefix 8 and suffix 0. - date-based versions, e.g. by distros (Ubuntu 18.04)
With the next release, will will make more clear how old a version really is. To do so, we change the version number slightly to
8.yymm.0
where yy is the two-digit year and mm the two-digit month of the release date. We release every 6 weeks, so we will never have two releases within the same month.
So the next version will be 8.1901.0 instead of 8.41.0. To make things even more clear, rsyslog visible version output will be even more up to the point: rsyslog -v will now report “8.1901.0 (aka 2019.01)“. I am right now implementing these changes. Continue reading “rsyslog version numbering change”
How we found and fixed a CVE in librelp
This is a joint blog post, from Adiscon and Semmle, about the finding and fixing of CVE-2018-1000140, a security vulnerability in librelp. This was a collaborative effort by:
- Kevin Backhouse, Semmle, Security Researcher.
- Rainer Gerhards, Adiscon, Founder and President.
- Bas van Schaik, Semmle, Head of Product.
We have published this post on Rainer’s blog here and the LGTM blog.

Bas originally found the vulnerability (using lgtm.com) and Rainer fixed it. Kev developed the proof-of-concept exploit.
In this blog post, we explain the cause of the bug, which is related to a subtle gotcha in the behavior of snprintf, and how it was found by a default query on https://lgtm.com/. We also demonstrate a working exploit (in a docker container, so that you can safely download it and try it for yourself). As a bonus, we give a short tutorial on how to set up rsyslog with TLS for secure communication between the client and server. Continue reading “How we found and fixed a CVE in librelp”
Why we use Static Code Analysis
We use static code analysis for two reasons. Both of them should probably be well-know, but discussions show that that’s not always the case. So I thought writing a small blog post makes sense.

The first reason is obvious: static analyzers help us catch code problems in early stages, and they do so without any special effort needed by test engineers. The analyzer “thinks” about many cases a human being does not think about and so can catch errors that are sometimes embarrassingly obvious – albeit you would have still overlooked them. Detecting these things early saves a lot of time. So we try to run the analyzers early and often (they are also part of our CI for that reason). Continue reading “Why we use Static Code Analysis”
rsyslog’s first signature provider: why Guardtime?
The new has already spread: rsyslog 7.3 is the first version that natively supports log signatures, and does so via a newly introduced open signature provider interface. A lot of my followers quickly realized that and begun to play with it. To make sense of the provider interface, one obviously also needs a signature provider. I selected the keyless signature infrastructure (KSI), which is being engineered by the OpenKSI group. Quickly, I was asked what were the compelling reasons to provide the first signature provider for this technology.
So rather than writing many mails, I thought I blog about the reason ;) Continue reading “rsyslog’s first signature provider: why Guardtime?”
Which data does the Guardtime signature provider transfer to external parties?
With the interest in privacy concerns currently having a “PRISM-induced high”, I wanted to elaborate a little bit about what rsyslog’s Guardtime signature provider actually transmits to the signature authority.
This is a condensed post of what the provider does, highlighting the main points. If you are really concerned, remember that everything is open source. So you are invited to read the actual signature provider source, all of which is available at the rsyslog git.
The most interesting question first: the provider does only send a top-level hash to the signature authority. No actual log record will ever be sent or otherwise disclosed. Continue reading “Which data does the Guardtime signature provider transfer to external parties?”