 The analysis of space shuttle Atlantis ECO-Sensor trouble continues. Everybody focuses now on the Feedthrough Connector.
The analysis of space shuttle Atlantis ECO-Sensor trouble continues. Everybody focuses now on the Feedthrough Connector.
I have been involved in some (heated ;)) forum discussion on why NASA takes the time to analyse the issue and not provide a quick fix now that the culprit is know (remember, the Feedthrough Connector has been identified as the trouble spot via the TDR data tanken on the last tanking test).
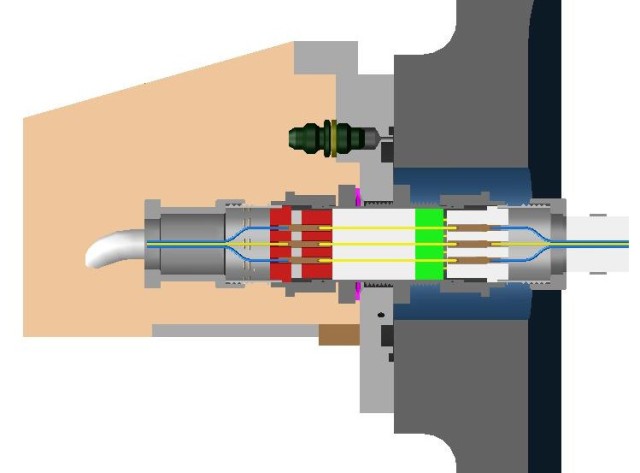
A quick wrap-up on the connector: it is used to feed several signals through from the tank’s interior to the Orbiter systems. Among them are the ECO sensors as well as the 5% sensor signal. The connection essentially consists of three parts. The schematic can be found in the small picture above (click to enlarge). I found a more detailed sketch in the STS-114 Flight Readiness Review (FRR) document:
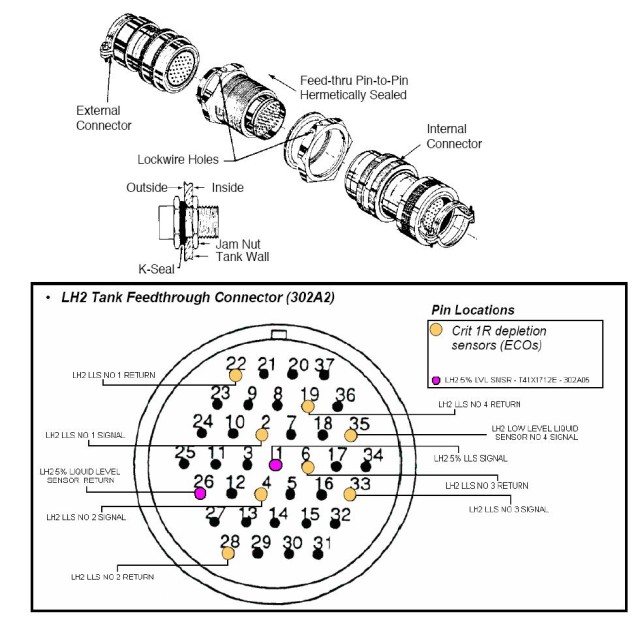 As you can see, the system consists of an external connector, the actual feedthrough that goes through the tank and an internal connector. As far as I know, the sole purpose of that system is to feed the internal signals through to the external stack parts while ensuring that there is no leak in the tank.
As you can see, the system consists of an external connector, the actual feedthrough that goes through the tank and an internal connector. As far as I know, the sole purpose of that system is to feed the internal signals through to the external stack parts while ensuring that there is no leak in the tank.
The external part of the connector has yesterday been unmounted and sent over the Marshall Space Flight Center for analysis. As far as I know, analysis results will be available on January, 3rd and will be the basis for the discussion on how to continue.
But back to my forum discussions. Why at all is an analysis been made?
There are a lot of technical words that could describe it. I will take a different route. I’d like to use a real-world analogy that most of us would probably be able to follow ;)
Let’s assume you own a house and it is xmas time. Chances are good you like to decorate your front yard with some nice lights. These lights need power and you need to draw that power from an outlet somewhere in, let’s say, your garage. Of course, the light’s power cord is to short, so you use an extension cord to connect the in-garage power outlet to the decoration’s plug in your yard. Everthing works perfectly and you are really proud of your fine lights.
But then, out of the sudden, a fuse blows and your lights go off. You begin to analyze the problem. One thing you notice is that it started to rain. But everything worked well a couple of times when there was rain, too. You blame the fuse, after all it was a pretty old one. So initially, you just go away with the issue, use a new fuse and be happy again.
After a while, on another rainy day, the fuse blows again. This time, you know it is a real problem. You do another analysis. In that course, you know that it must somehow be related to the extension power cord (let me just assume you somehow magically know it is ;)).
This is where we are with the ECO sensor system currently. The extension power cord is my analogy of the feedthrough connector. Testing done during the tanking test pointed at that connector, just as you now know it is the extension cord. However, test data did not say exactly what is wrong with the connector. In my sample, we also do not know what’s wrong with the extension cord.
Back to the sample: so what to do? If do not want to do a more in-depth analysis, we could simply replace the extension cord (just like we replaced the fuse) and hope that all is well. This might work, especially if we had little trouble in the past. It is also a quick fix, which is useful a few days before xmas (aka “time is running out).
If we take a bit more time, however, we might want to analyze what the root cause is. If we do, we may find out that the extension cord indeed was faulty. Maybe its water protection was damaged. Then, we’ll end up with swapping the cord, but this time with a very good feeling and confidence that our lights will stay on.
But analysis may also show less favorable results: maybe we find out that the cord is perfectly OK. But we made a “design error”. Maybe we find out that we used a non-outdoor rated cord in our “yard light system”. Replacing that cord with a like part would bring no improvement at all. In this case, we would need to do some more change – using an outdoor rated cord would be appropriate. Again, we could modify our power supply and have a very good feeling about its future reliability.
Unfortunately, space hardware is a bit more complex than xmas decoration. So analysis takes a bit longer. But it still offers the same benefits: if you look at the root cause AND be able to find it, you can reliably fix the system. Of course, there are limits and constraints. Too large delays bear other risk. It is NASA management’s task to weigh benefit and risk and do the right thing.
Oh, and one more note: I’ve heard so often “NASA just needs to do fix and everything will be easy. Just throw out that feedthrough connector…”.
Let me use my xmas decoration analogy once again. What that means is that you get a big digger and get rid of the extension cord at all – by creating a permanent electrical circuit with its own fully-outdoor-proven outlet right at the decoration. Of course, this is doable. Of course, it’ll fix the problem. It is just a “simple redesign” of your system. If think, however, that it is not the real smart answer to the problem you faced.
And I think many of all those quick fixes now being proposed “just let’s redesign the shuttle…” are along the same lines. If, of course, they were technically sound… ;)
I hope my sample helps clarify why there is analysis on the ECO sensor problem and why this is a good thing to have. Even though it may push Atlantis launch date a bit further down the calendar.




