I am thinking quite a while about doing online seminars or meetings for folks interested in rsyslog. After some prep work, I decided to do an experiment and invite all of you to the rsyslog community’s first open online meeting. It will be held at 2020-09-29 at 3p UTC (5p CEST, 11a EDT, 8a PDT). The meeting URL is https://meet.rainer-gerhards.de/syslogOpenMeeting. Meeting language is English.
Rainer Gerhards preparing a Video Conference.
This is more than a community experiment. I have worked on setting up a decent self-hosted Jitsi Meet server (some background info in German). The meeting is also meant as one of the first test runs for this system. So it definitely helps if you are a bit adventurous when you attend.
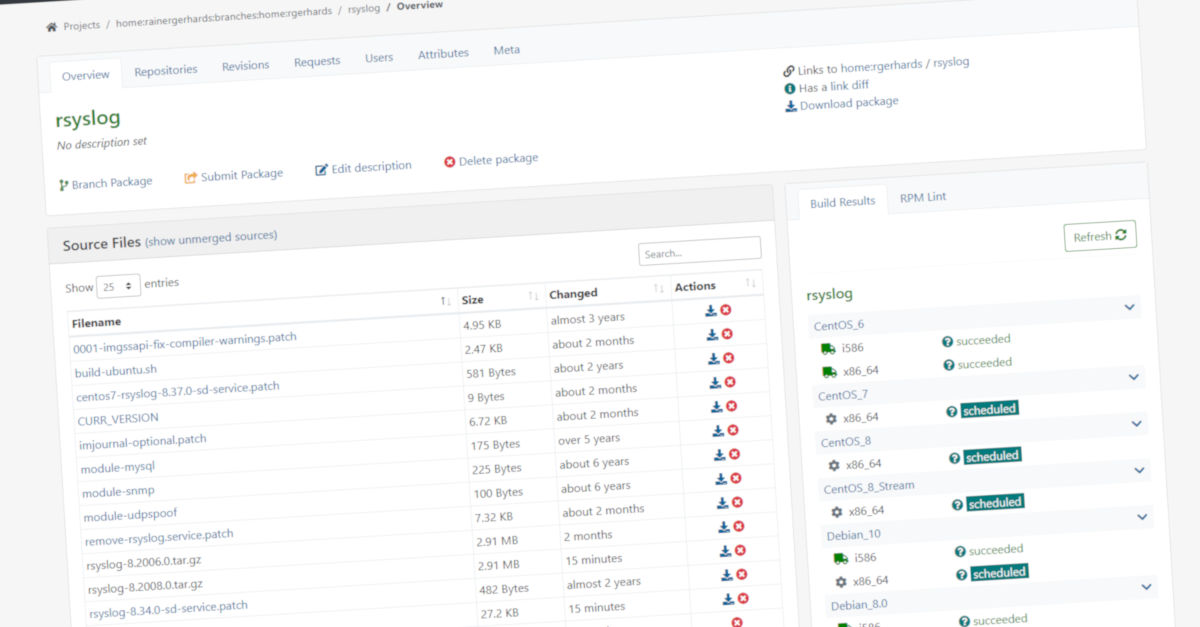
A rsyslog build via SUSE Open Build Service. This time the rsyslog package build process is delayed due to problems with upgrades to the package build process. (Image: Rainer Gerhards)
The rsyslog project usually publishes binary packages for many distributions alongside the regular (source) scheduled stable releases. So far, this was a mostly manual process. In the past couple of week, we have worked on a CI system for package build as well as additional automation. We have not yet fully reached our goals, but things look pretty well.
Did you search for “rsyslog template variables”? And landed here? Many folks do, so let me explain where you actually find them. TLDR: find them in the property doc.
This tutorial tells how to integrate data from Windows event log into our rsyslog configuration. We will do this integration via the UDP syslog protocol so that we finally can show this in a real case. No advanced topics are covered. We use CentOS 7 and Windows Server 2012 (because it still is in more widespread use). This is part of a rsyslog tutorial series.
This tutorials tells how rsyslog is configured to accept syslog messages over the network via UDP. No advanced topics are covered. We use CentOS 7. This is part of a rsyslog tutorial series.
Scope
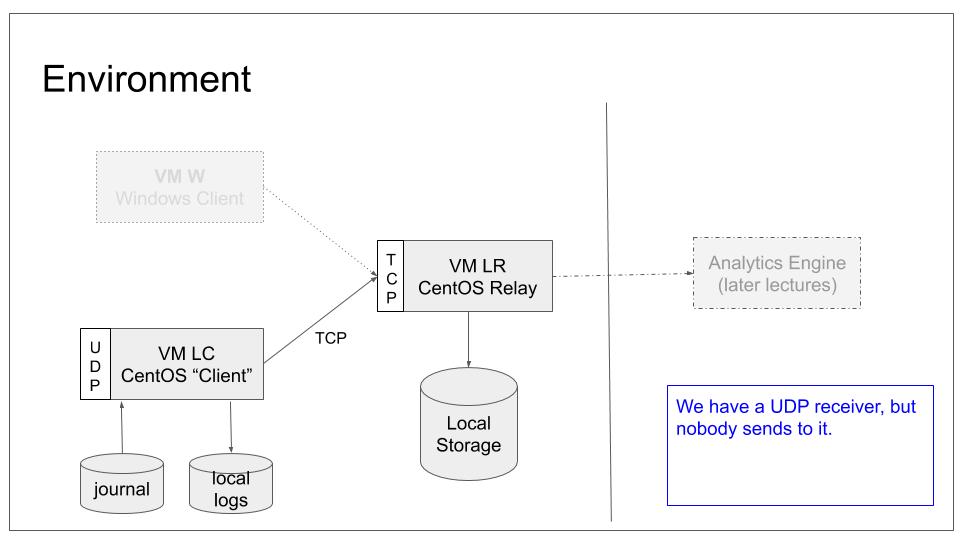
We will configure LC to only relay messages received via UDP but not store them locally. Locally-generated messages will still be stored inside local log files. They, too, will be forwarded to LR. This is a very common use case. We still do not configure any sender to connect to LC.
To do all of this, we need to modify only LC local configuration. As such, our base lab scenario will remain in the following configuration:
Note that we still do not configure any system to actually send data to LC. This will be done the next tutorial. Note that if you did not complete the last tutorial, it may be wise to have a look at it. We will work with the configuration it generated. Continue reading “rsyslog: relay messages only (no local storage)”
This multi-step tutorial series targets rsyslog beginners. It covers typical configuration steps which are done with minimal effort. I found that for beginners it is often very important to provide precise instructions for their specific environment. As such, I focus on CentOS 7, which is quite popular in enterprise environments.
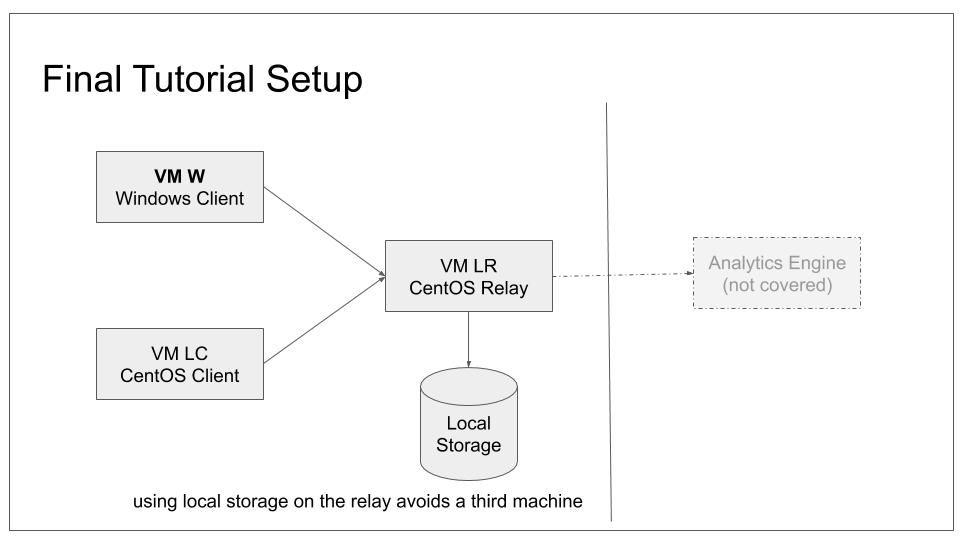
Final setup at end of basic tutorial set.
If you do not usually use CentOS 7, I still suggest to download and install it on two lab machines. This permits you to follow the tutorial in exact steps. Once you know what you do, it should be fairly easy to translate that to other distributions like Ubuntu.
Note: I am currently writing the tutorials, so they will grow for the time being. The basic set will have around 10 tutorials (I already have the full outline).
Available Tutorials
For best experience, read tutorials in given order:
Note that if you are interested in a specific topic, you can also pick tutorials out of the order. Be warned, though, that there is some inter-dependency between the tutorials. For example, for forwarding messages, a server is needed. The forwarding tutorial as such assumes that the server was properly created. In suggested sequence, this is ensured.
There exist also some utility tutorials to help you understand the operating environment. They are linked to from the appropriate places.
Why is this tutorial series created and hosted here? Find the answer in this article. If you are interested in contributing to the effort, please let me know. Feedback of any kind is also very welcome. You can also use the comment fields to provide it.
This tutorials tells how rsyslog is configured to accept syslog messages over the network via UDP. No advanced topics are covered. We use CentOS 7. This is part of a rsyslog tutorial series.
Scope
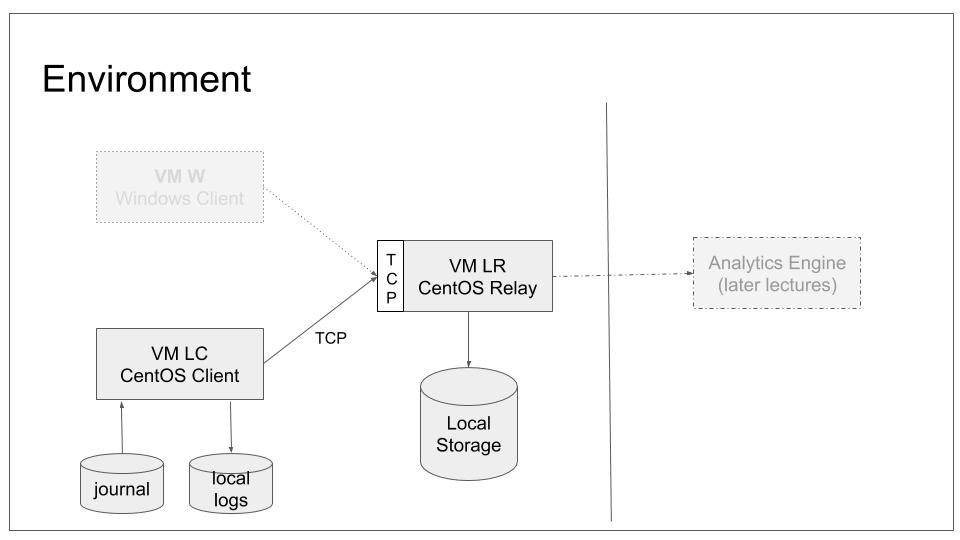
We will configure the relay system to accept UDP based syslog from remote ends. We do not, however, configure any sender to connect to it. We will use LC as UDP server, just so that we get some more variety into our lab with limited systems. In our base lab scenario, this will lead to the following configuration:
This short tutorial explains everyday service management. While it claims to address management of rsyslog, it actually describes the tools for all services. The tutorial is written for CentOS 7, but should work equally well on other systemd-based systems like CentOS 8, recent Fedora, recent Debian and recent Ubuntu. Continue reading “How to start, stop and query the status of rsyslog (on a systemd system)”
This tutorials tells how rsyslog is configured to send syslog messages over the network via TCP to a remote server. No advanced topics are covered. We use CentOS 7. This is part of a rsyslog tutorial series.
Scope
We will configure an end node (here: LR) to send messages via TCP to a remote syslog server. We do not apply local pre-filtering and we want to make only minimal changes to the CentOS 7 default configuration. In our base lab scenario, this will lead to the following configuration:
This tutorials tells how rsyslog is configured to accept syslog messages over the network via TCP. No advanced topics are covered. We use CentOS 7. This is part of a rsyslog tutorial series.
Scope
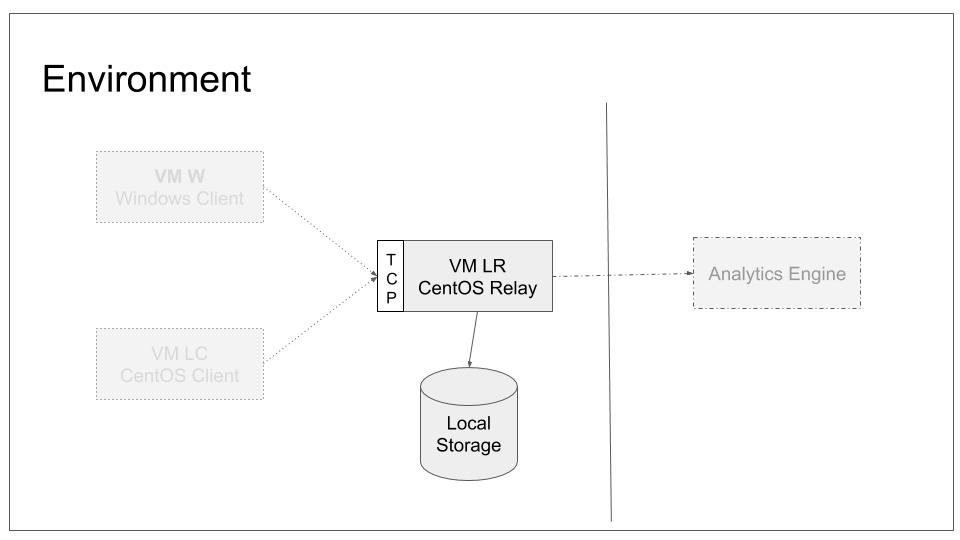
We will configure the relay system to accept TCP based syslog from remote ends. We do not, however, configure any sender to connect to it. In our base lab scenario, this will lead to the following configuration:
rainer.gerhards.net uses cookies to ensure that we give you the best experience on our website. If you continue to use this site, you confirm and accept the use of Cookies on our site. You will find more informations in our Data Privacy Policy.