
Hi all, as you probably know, my blog’s design hasn’t changed in ages (yup, I’m a conservative guy). However, it finally is time to update things, so I’ll look at some new design (and maybe software) options. That means that the blog may be a bit under construction during the next couple of days. Please pardon any problems associated with that — they will be temporary.
Adiscon LogAnalyzer 3.3.0 beta is out
Adiscon’s open source log analysis frontend LogAnalyzer has grown with some exciting new features. Most importantly, report generation speed has been much increased. This was made possible via tighter integration of the report logic with the actual log source (database or file). As a result, all reports are generated in considerably less time and require far fewer system resources to complete. Along the same lines, Adiscon LogAnalyzer now offers suggestions for indexing database sources. If it finds room for improvement, new indexes are automatically suggested. This results in overall improved speed throughout the application.
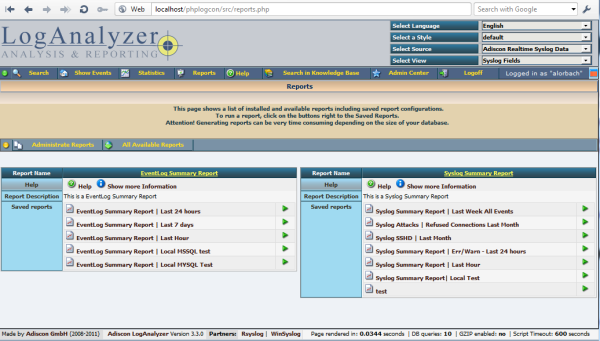
Also, finally a long-due user interface improvement has been made: to access the reporting feature, users needed to access the admin panel. This was kind of well-hidden and cumbersome. In 3.3.0, reports are directly available from Adiscon LogAnalyzer’s main panel. With this change, some users may even discover the reporting feature for the first time. The screenshot below gives you a sneak preview of the new interface.
Best of all, the new version has brought some under-the-hood improvements that we will utilize in the future to generate some really exciting new reports. Stay tuned, there is much more to come…
And finally let me say that work with the LogAnalyzer team to improve integration into rsyslog and the Adiscon’s Windows logging components. We are trying very hard to provide an easy to use, integrated solution.
thinking about a rsyslog client for Windows…
I have had a series of interesting talks during the past weeks. We at Adiscon have seen that there is high demand for closely integrating Windows machines into an rsyslog enterprise logging infrastructure. Of course, there are various ways to do that, and probably the best is using Adiscon’s other members of the MonitorWare product line. However, we can obviously go one step further and provide even thighter integration. For that reason, we will most probably soon create a special software package, the rsyslog for Windows client. It will provide
- Event Log Forwarding
- Log File Forwarding
- Syslog Relay
capabilities, probably in different editions so that users can cover exactly their needs. While event log and file forwarding seem natural, syslog relay functionality may be a bit surprising, given the fact that rsyslog is available as a direct receiver. This feature is primarily targeted towards larger enterprises which may have no Linux machines in remote offices, but equipment they need to monitor via syslog. The core idea here is that we provide that functionality on a Windows box, which can than talk to the central rsyslog server via a reliable way.
We are currently discussing the details of this plan. I hope we will be able to show first results soon.
liblognorm event annotation … and CEE
As you probably know, CEE is an effort driven by MITRE to support a common event expression format. Liblognorm is a log normalizer library (aka “network event normalizer”). One of its primary target formats is CEE.
For pure normalizing needs, liblognorm extracts data fields from semi-structured log message. The extracted fields are available inside a (basically) name/value property list. Liblognorm also permits to classify messages, e.g. as being a logon or logoff message. For this classification, liblognorm provides so-called “tags”. These are simple words (strings of characters) which can be specified by the user. Tags reside in a special property called “tags”, but otherwise occupy a flat space (tags can easily be structured via punctuation).
CEE takes a slightly different approach: while it shares the tag concept (actually liblognorm inherited tags from an earlier version of CEE), CEE classifies tags into different tag types. For example, “logon” may be a tag, but can only be used to describe an action(-field). As such, “logon” can not be present by itself in a CEE log record, it must be given as value of the action field (‘action=”logon”‘). Also, CEE requires some other fields which may not be present explicitly from the original message even though the information may implicitly be present inside it. To express such information entities (and tags in the CEE way), liblognorm needs the capability to add additional fields to an extracted event. Let call these set of fields the “annotation” for easier future reference. Liblognorm needs to annotate the event so that the target format’s (CEE) requirements are met. While I was talking about CEE so far, I assume (and know from previous experience) that other formats may have similar requirements, albeit different fields that need to be annotated.
The question is now: how to implement this in liblognorm? The initial idea was to include the annotation inside the normalization rule itself. That has a major drawback: If a rule base is to be used for CEE and some other format, the annotation may be different, and thus the same rule base cannot be used. These two rule bases would differ in just the annotation. So it seems more natural, and easier to maintain, to split the recognition rule from the annotation rule. In that setting, the message is recognized and classified by recognition rules and the annotation is based on (different) annotation rules. So only one set of recognition rules can be used by multiple annotation rules. Only the latter need to be redefined for different target formats (or systems).
This split-rule method is the way I intend to head to. In essence, the current “rule=” rule and its format will remain untouched. It will be augmented by “annotate=” rules, which contain the full annotation. The binding between these two will be done via classification (liblognorm tags): in the first step, the message is recognized, data extracted and tags assigned, just like it is currently done. Then a second step will be added. It traverses through the tags and adds all annotation that are defined for the message’s tag set. So the binding is on the tag set. Finally, it is probably necessary to add a third step that can remove unwanted fields. This step is probably target-format specific. For example, this step could eliminate the liblognorm tag set from an event if CEE compliance is desired, because CEE does not support, not even permit, an extra tag set.
Feedback on this approach is appreciated. It is my hope to be able to implement this in the near future.
filler fields in log normalization
When looking at some real-world rule bases for liblognorm, I noticed that it is often required to check for the presence of a specific field, but the value is actually not needed. This leads to fields named e.g. “filler”, “dummy”, “dummy<n>” with n being an increasing number. This is both clumsy and requires unnecessary processing power. For that reason, I have introduced “-” (dash) as field name. When this special name is used, the field as parsed as usual, but immediately discarded after the successful parse. So while we need to parse and extract in order to get the parse logic right, we save the effort to keep a copy of this unneeded data. This also means that output log records produced by the normalizer tool are cleaned up. I hope this is a useful addition.
Paper on LogNormalization
I wanted to make all of your aware that I have posted a paper on log normalization . This was originally done in regard to CEE, but I noticed that the classification of different log sources and the way to handle them is of broader use. I hope you find the paper useful.