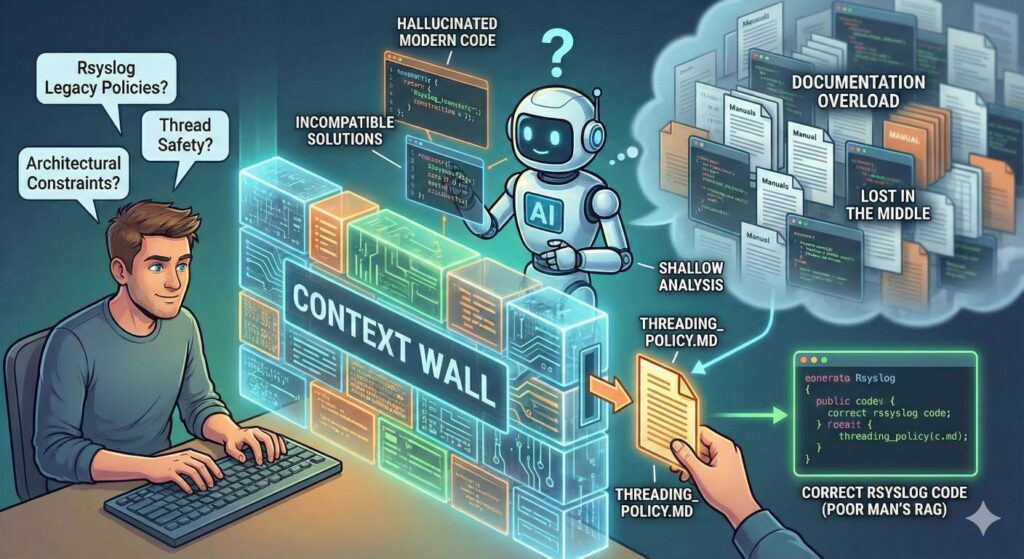
If you want the CS summary: it is at the end.
I keep seeing the same take pop up: “AI is overhyped. Mostly money burning.” Sure. There is hype. There is also a whole lot of low-effort “vibe coding” that produces low-quality output at impressive speed.

But there is also something else: if you treat AI as a serious engineering tool and you are willing to do the unglamorous work, it can make measurable difference and boost productivity and quality.
So here is a concrete case study: agentic code work in rsyslog.
Continue reading “AI Code Generation in a 200k LOC C Codebase: What Actually Worked in rsyslog”